

Understanding the TCP RST Issue in the Call Center Application
A while ago, our company took part in a national HW project. Although the overall support process went smoothly, a few minor issues arose. Here, we revisit and document the troubleshooting steps taken to resolve a call center business application crash related to a TCP RST issue.
After the HW project began, the call center started experiencing frequent application crashes and disconnections on the agent side, negatively impacting the customer experience. The issue was quickly escalated to the Information Technology Department for further investigation. Initial checks by the application system manager revealed intermittent problems with the TCP connection between the intranet client and the server, with the TCPing port occasionally failing to respond. This led to suspicions that the internal network might be unstable.
Steps for Diagnosing the TCP RST Problem
When analyzing suspected network failures, what should we do? First of all, we must have the ability to argue and not take the blame.
Well, those who have the confidence can do so.
Generally speaking, there may be the following points: understand the fault phenomenon, clarify the network topology, sort out the data flow, and reasonably deploy packet capture points.
Because the feedback interaction from the person in charge of the application system was relatively simple and the failure phenomenon was random and frequent, and the remote call center client did not have the technical ability to capture packets, packet capture was performed on the server side, and the packet capture point was on the server gateway switch.
Analyzing the TCP RST Data
First, we filtered and captured the data packets based on the reported client 1 IP 192.168.0.1 to see if there were any abnormalities.
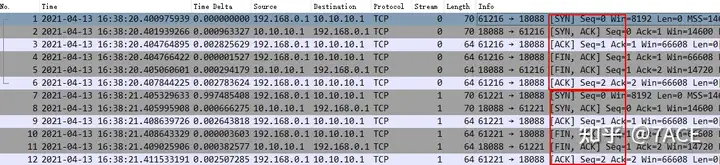
The TCP layer regularly establishes and closes connections, which should not be a problem, just the heartbeat packets between the client and the server. Then pick up the only stream with data fields transmitted, and it seems that there is no problem in the corresponding time. Data packets with [PSH, ACK] and [ACK] are exchanged back and forth.
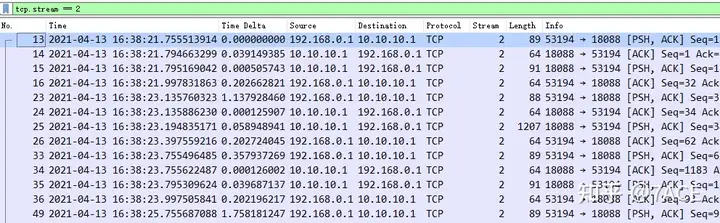
The first analysis attempt did not seem to obtain any useful information, so I emphasized to my call center colleagues that the client source IP and the time when the application crashed needed to be further clarified, otherwise the packet capture analysis on the server side could easily be obscured by a large number of data packets.
The second time, based on the reported problem, the client 2 IP 192.168.0.2 , the server IP 10.10.10.2 and the failure time (within 1 minute) were filtered and captured, as shown below
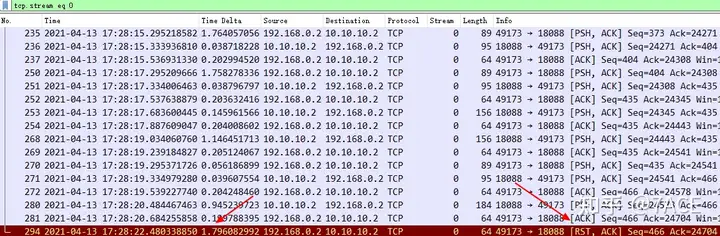
It was found that the client actively RST the connection, and there was no retransmission caused by delay or packet loss on the network. During the time of the failure, the communication between the client and other servers was observed and the same problem was found.

The client also actively RST’d the connection around the same time. Based on the corresponding data packet phenomenon, the problem is more likely to be with the application itself.
To further support the conclusion, we once again traced back and analyzed the data packets of client 3 IP 192.168.0.3 at the time of the failure, and found the same phenomenon with no other abnormalities.

Comprehensive Analysis Points to an Application-Related TCP RST Issue
Based on the problem phenomena reported by the business, a comprehensive analysis of different clients, servers and different fault time points showed that the problem was not on the internal network (including the dedicated line interconnecting the call center and the headquarters), and all that was seen was client behavior. The person in charge of the feedback application system needs to further check the fault logs on the application.
The person in charge of the subsequent application system retrieved the application log on the client and found that the application had failed to call the service at the time of the failure, which then caused the application to crash. After analysis, it was found that the application would call the public network service when handling a certain business, that is, the local client of the call center would generate an outbound access from the public network to the server in the DMZ area of the headquarters data center. Due to security HW requirements, the call center closed the public network access, which caused the call failure and the application crash. The RST data packets captured in the intranet were all subsequent behaviors generated after the application crashed and closed, and the problem was solved.
Conclusion: Best Practices for Resolving TCP RST Issues in Call Center Applications
The troubleshooting process highlighted several important practices:
- Identify Fault Symptoms: Use application logs to understand the exact cause of TCP RST issues.
- Map the Network Topology: Clarify client-server relationships, network components, and interaction methods.
- Examine Data Flow: Analyze data paths, types, and interaction rules to ensure no details are missed.
- Deploy Packet Capture Strategically: Capture network traffic at multiple points to get a comprehensive view.
By following these steps, similar TCP RST issues in call center environments can be addressed more effectively in the future.